Some notes on Web Scraping
These are some of my basic notes on manual web scraping. Note that for common platforms like Youtube or similar, there's often already a tool out there, so it may be preferable to look for something that's already written if you're wanting to do something like ripping videos from Youtube, or ripping images from Reddit, etc. Still, being able to manually write a scraper can be useful when needing to mine data from obscure sites, or for building custom enumeration tools for diverse situations.
Note also: Many platforms forbid automated scraping!!
Making or using scrapers can sometimes be perceived as a hostile act due to the fact that it can often consume bandwidth, can deny the site owner ad revenue or the ability to sell API keys , and may result ToS violations, bans, or other...trouble.

In other cases, site owners may not care...
So make sure you understand the ToS of the platform you intend to scrape, and don't scrape when told not to.
dO i nEEd tO KnOW pyThON?/?
No.
Scraping can be accomplished in any language that can do the following:
- some kind of facilities for making HTTP requests
- some kind of HTML parser
- some sort of regex and string manipulation facilities
- good flow control structures, like for and while loops
That's really it. I usually write scrapers in BASH using hxselect as my html parser and grep for regex, along with some shenanigans like using cut, tail, etc for various types of manipulations. You could also do it in PHP using PHP's cURL bindings,and DOMDocument and loadHTML() for parsing, and the preg* series of functions for regexes. You could probably go nuts and write a scraper in C using libCurl and libXML2 for parsing if you really wanted to waste your time, but whatever.
Python is popular because it's HTML parser, BeautifulSoup4 is well known, and it's requests library is simple to use. However, Python itself isn't strictly necessary, and it isn't the language I typically use for scraping. Scraping is even one of the example use cases given by the Python tutorial called Automate The Boring Stuff, but again, we don't strictly need it.
Cases for automation
- When there's a large number of regular pages you need processed
- When there's a regular case for the need to process a page or type of page
- One case of this is if you're regularly calling out to frequently changing data
- Another case is web tool development -- i.e. when you're parsing for specific types of information across different sorts of pages.
Development method
- Enumerate, ingest and inspect
- Pull down a working copy of a sample of the page you want to scrape
- Inspect the raw HTML, in both a text editor and with dev tools
- identify pertinent items (links, images, etc)
- Parse and process
- Using HTML parsers, regex and string operations, how do we isolate the pertinent data?
- Generate output
- Are we merely downloading something?
- Do we need some sort of format conversion tool between our scrape and the final product?
Depending on your project, this process will probably be iterative. For example, if you wanted to write a scraper to steal all of the images out of my message board, you might (in pseudo-code), do something like this:
download mb.php
parse mb.php for links to each of the board's pages
for ($i=0;$i<sizeof($numberOfPages);$i++){
download mb.php?page=$i
parse the above for links to each thread
for ($j=0;$j<sizeof($threadLinks);$j++){
download mb.php?thread=$threadLinks[$j]
parse the above for links to each image
for ($k=0;$k<sizeof($imageLinks);$k++){
download /img/$imageLinks[$k]
write download to disk as final output
}
}
}
This should be O(n^3), and illustrates how the process of getting to our final product can be iterative.
Parsing and processing
So for an example in bash, let's say we're doing what I said above, and you want to scrape images off of my imageboard.
I'd start by just doing a pull of the board with wget to get a sample page. So something like wget https://glowbox.cc/mb.php.
Once I have this, I'll give the HTML returned a manual lookover and identify the parts of it I want.
So here I can see each individual post:

And we can also see the image and the link to the image.

Playing with the site, I know the link will take me to the full version of the image, so let's run this through a parser to filter for all <a> tags.
First off, if I try anything with my bash parser, it throws an error because this isn't "clean" HTML. So we'll output some clean HTML like so:
hxclean < mb.php > mb_clean.php
This will produce cleaned HTML that my parser can output on.
Now lets pull all of our <a> tags.
hxselect -s "\n" -c 'a::attr(href)' < mb_clean.php
a::attr(href) is a CSS selector telling the parser that we want to see the content of the href (the link location) attribute of all <a> tags on the page. This gives us:
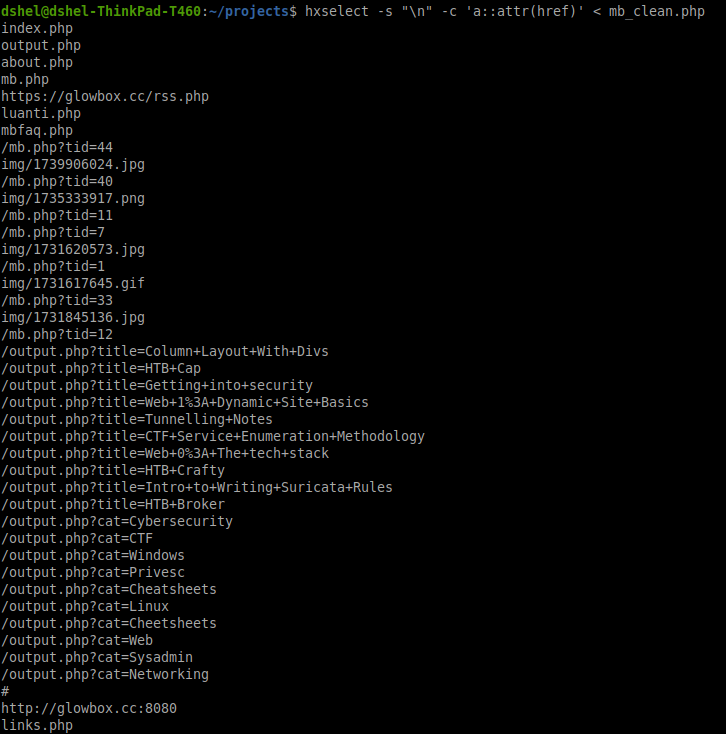
We can see that the links we probably want are these, that are in the /img/ directory:
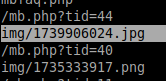
Now that we've parsed the HTML, we can use regular expressions to refine further. In this case, we can simply pipe our command into grep:
hxselect -s "\n" -c 'a::attr(href)' < mb_clean.php | grep 'img/'
This gives us the gold:

This is kind of our final point in parsing (since we have what we want). What we need to do now is assemble the logic for the script and totally automate things. Time for a new section header lol.
Assembling the logic and stealing my images!
So from the above section, we have the following hands-on-keyboard logic:
hxclean < mb.php > mb_clean.php
hxselect -s "\n" -c 'a::attr(href)' < mb_clean.php | grep 'img/'
Firstly, we know we got mb.php from a call to wget, so we'll need to integrate that somehow. Secondly, we don't want to do file access when we could simply shove this into a variable, so we'll do that too.
To do this, we might restructure things like this:
mb_dl=$(wget https://glowbox.cc/mb.php -q -O -)
IFS= read -rd '' mb_content < <(echo "$mb_dl" | hxclean)
This is pretty obscure, but effectively, we create a variable called mb_dl to hold the raw HTML as pulled from wget (which we run -q quietly, and with -O - to suppress the output file). This is then, in a convoluted way, run through hxclean and stored in the variable mb_content. The stuff with redefining the IFS character has to do with text formatting issues some methods for populating variables can cause.
From here we can do our parse:
hxselect -s "\n" -c 'a::attr(href)' < <(echo $mb_content) | grep "img/"
However, we don't want to just end on getting the list of links -- we need to actually download them, so we'll shove the above outputs into an array and then run through a for loop.
content=$(hxselect -s "\n" -c 'a::attr(href)' < <(echo $mb_content) | grep "img/")
IFS=$'\n' read -d "\034" -r -a array <<< "$content"
for element in "${array[@]}"
do
wget https://glowbox.cc/$element
done
That should store the parsed links as a variable called content, split the parsed link list into an array (the IFS line) named array, and then iterate through that array, doing a call to wget on each element of the array.
All assembled, then, out work should come out to something like this:
#! /bin/bash
mb_dl=$(wget https://glowbox.cc/mb.php -q -O -)
IFS= read -rd '' mb_content < <(echo "$mb_dl" | hxclean)
content=$(hxselect -s "\n" -c 'a::attr(href)' < <(echo $mb_content) | grep "img/")
IFS=$'\n' read -d "\034" -r -a array <<< "$content"
for element in "${array[@]}"
do
wget https://glowbox.cc/$element
done
And congrats, that's a quick and dirty scraper to pull all of the top level images off of the first page of my board. That's not too complex, but it shows the concept.
If we wanted to push further, like I said above, we could get iterative with it, and nest several for loops together, in order to parse threads, pages, etc, and steal everything, but that's a bit more than I'm going to do for a quick example like this.
But BASH is obscure and slow...
Ok, let's do it in PHP.
<?php
//grab the mb.php HTML
$content = file_get_contents("https://glowbox.cc/mb.php");
//setup DOMDocument for HTML parsing
$doc = new DOMDocument();
libxml_use_internal_errors(true); // Prevents warnings from malformed HTML
//actually load what was pulled down
$doc->loadHTML($content);
libxml_clear_errors();
//Parse out <a> tag href params and assign to array $hrefs[]
$anchors = $doc->getElementsByTagName('a');
foreach ($anchors as $anchor) {
$hrefs[] = $anchor->getAttribute('href');
}
//parse $hrefs for those containing img/ directory.
$imgs = preg_grep('/img\//', $hrefs);
//reset the array indexes from 0 after the grep
$imgs = array_values($imgs);
//grab and save the images:
for($i=0;$i<sizeof($imgs);$i++){
$file = basename($imgs[$i]);
$fp = fopen($file, "w");
$img_file = file_get_contents("https://glowbox.cc/$imgs[$i]");
fwrite($fp, $img_file);
}
?>
While the code is less compact, it is a bit easier to understand, and executes about 2x as fast as the BASH script.